
Summary
We needed to find a solution that would allow us to run background processing jobs on ECS cluster in AWS. There were a lot of challenges related to scaling and logging infrastructure but we were able to find solutions for those. It was an interesting dive into ECS and AWS in general.
We ended up creating an ECS Cluster for background job processing that scales, collects logs. With some fine-tuning it can be adapted for web applications (by adding ELB / ALB, Service Auto Scaling). We hope that you will find this useful for your projects and you will end up saving time. Your feedback is welcome.
Intro
We were searching for a place where we could run background processing jobs on AWS. Putting jobs into Docker containers looked like a good fit since jobs itself does not have internal state (database, etc).
Our first choice was to use AWS ECS to run such jobs if we could wrap those jobs into Docker containers. It made a lot of sense from price point of view as we could use resources more efficiently.
We did some analysis and testing and thought that it would make sense to share our findings. We ended up preparing ECS cluster that auto scales and collects logs for running any general background processing task.
We implemented:
- ECS cluster
- Scaling based in reserved memory
- Draining of instances using Auto Scaling Group Lifecycle hooks
- fluentd + ElasticSearch for logging
Problem statement
Background processing jobs
- There are lots of jobs: 100+
- Every job is different in some way
- Some run every minute, some every day
- Runtime: from 1 second to 8 hours (worst case)
- Currently all jobs run on same stack (PHP, etc), but that may not be the case in the future
From description in seems that ECS would be good fit if we Dockerize every job and run them on Cluster.
What’s the benefit of using ECS?
- Shared resources. One cluster, multiple applications
- A place to run Docker containers + benefits that come with Docker (e.g. isolation and independent deployment)
- Cost
What is ECS and Why should I care?
ECS – Amazon EC2 Container Service. Works on top of EC2. Allows to run and manage containers using AWS APIs.
Some terminology used assuming you’re familiar with AWS and Docker, but not with ECS:
- Cluster – multiple EC2 machines with Docker that forms a cluster
- Container Instance – EC2 machine which is attached to ECS cluster
- TaskDefinition – similar to
docker-compose.ymlfile. Definition on what containers are used for application and how they are connected together - Task – TaskDefinition running on some instance. Task is one-time run. If it dies – it does not get relaunched.
- Service – layer on top of TaskDefinition which says how many instances (number) of TaskDefinition should be running in Cluster. Service launches Tasks and ensures that specified amount of Tasks are running
How does jobs look on ECS?
We decided that Service does not make sense for jobs in context of ECS, because Service is something that should be constantly running on ECS cluster:
So mapping goes as follows:
- TaskDefinition – job (how often should it run, configuration, which containers)
- Task – one instance of running job. Running job means running Task. There may be two instances of same job running at the same time (if job is designed for that).
Scheduler is needed. Main function of Scheduler would be starting jobs (Tasks) at appropriate time.
Overview diagram
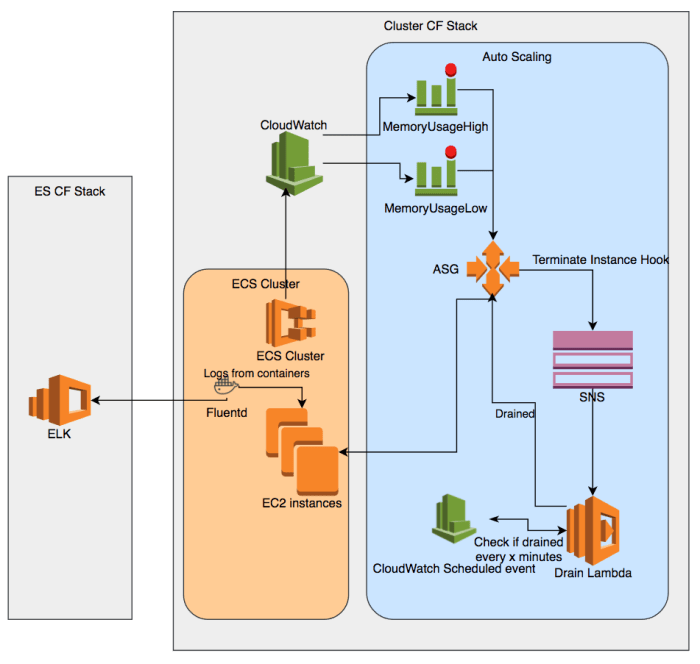
Scaling
There are two types of Scaling available in ECS:
- Container Instance scaling – using Auto Scaling Groups
- Service Auto Scaling – Scales number of running Tasks in Service based on metrics
Since we don’t want to use Services we only care about scaling Container Instances
To avoid confusion, some scaling terms:
- Scaling Out – adding more instances (nodes) to the cluster
- Scaling In – removing instances (nodes) from the cluster.
- Scaling Up – adding more resources to node
- Scaling Down – removing resources from node
Scaling Out
Each Task Definition defines how much memory it needs to run. Starting a Task on Cluster means finding Cluster Instance that has enough resources not yet reserved to run that Task. If resources are not available – Task fails to start.
We need to make sure that we Scale the Cluster out when available resources reaches some threshold.
A good blog post about scaling up can be found here
If we don’t want to write our own metrics there are only two reservation metrics available:
- Memory Reservation
- CPU Reservation
We chose Memory Reservation because it made most sense for jobs.
Rule of thumb: you always have to have capacity to launch the biggest task you have.
Threshold = (1 - max(Container Reservation) / Total Capacity of a Single Container Instance) * 100
In general there are more questions to consider and tune timings:
- How long does it take for new instance to start?
- How many instances to launch when scaling out?
- How to properly set memory reservations?
- How many tasks can run on one Container Instance?
Scaling In
The fun part.
For metrics we can just use Memory Reservation. Set it to some conservative value like only 20% memory reserved and Scale In.
Choosing instance to terminate
Ideally on scale in we would find an instance that does not run anything and terminate it. You can find list of possible configuration options for choosing an instance in documentation. However there’s no such option as “does not run anything” so in general any instance can be terminated.
Why is this a problem? We can’t terminate an instance that’s still running some jobs and we can’t really control which instance to terminate. Another problem is that longest running job may take around 8 hours to complete (worst case).
ECS Cluster also does not know anything about instance termination. In theory Cluster could start running a task on machine after Auto Scaling Group decided to terminate. That could also cause problems by terminating instance that’s still running a Task.
Draining state
Early 2017 Amazon introduced new state for Container Instances called “Draining”. You can see more about “Draining” state in documentation.
In general there are two states currently possible for Container Instance that’s attached to Cluster:
ACTIVE– default state, instance is operational and running TasksDRAINING– special state when instance remains in cluster but new Tasks are not scheduled on Container Instance
A catch here is that Auto Scaling Group does not set Container Instance state to DRAINING but you can do it through console or API. You may also need to update the SDK because this feature is fairly new and old SDK does not support this. At the time of writing SDK which is bundled with Lambda scripts currently does not support this feature.
Auto Scaling Group Lifecycle hooks
How ideally we would want to approach this problem:
- Auto Scaling Group decides that it needs to kill an instance
- Set Container Instance state to
DRAINING - Wait until Container Instance finishes running all Tasks
- Terminate Container Instance
Here’s where Lifecycle hooks come into play. Lifecycle Hooks are not visible in AWS Console (at least I could not find it), but can be seen through APIs.
How it works for terminating:
- A hook is registered on Auto Scaling Group
- Hook is triggered when Auto Scaling Group needs to terminate an instance.
- Hook is sent to SNS Topic / SQS Queue / CloudWatch Event
- Auto Scaling Group waits for Hook to complete or timeout before terminating an instance
Timeout of a hook can be extended by sending a heartbeat up to 100 heartbeats but for no longer than 48 hours.
In case of termination end result is terminate. Which means that if Auto Scaling Group decided to terminate an instance it will terminate the instance but it can be delayed with Hooks for up to 48 hours.
Lifecycle hooks can also be used to ensure that Tasks finished running when upgrading instances for example and since it’s a feature of Auto Scaling Groups it could be used in other cases not related to ECS.
Implementation
There is an implementation example published in AWS blog. It works by triggering Lambda code which sets DRAININGstates, checks for Tasks on Container Instance and completes Hook when Container Instance is drained.
However there is one big problem in this implementation: it works by resending Hook to the same SNS topic to trigger same Lambda code (cyclic dependency). This means that Lambda is triggered very often by SNS and runs more than 10 times a minute. This way we could exhaust our limit of 100 heartbeats very fast.
We ended up improving upon this implementation. We added CloudWatch Event schedule rule that triggers every 6 minutes. When Lambda needs more time to wait or registers itself into CloudWatch Event and gets triggered again later.
6 minutes is important here because there can be no more than 100 heartbeats registered. 6 * 100 / 60 means that our instances would stay for maximum of 10 hours and will be checked for no running tasks every 6 minutes.
Scaling policy types
Since Container Instance could be in DRAINING state for long period of time it is important to appropriately configure Scaling policies.
Generally there are two types of Scaling policy types:
- Simple Scaling Policy (default)
- Step Scaling Policy
One big drawback of Simple Scaling Policy is that it only performs one Scaling action at a time and additionally waits for Cooldown period before performing another Scaling action. Cooldown period starts only after action is completed. When combined with Draining this would mean that Scaling Out would not happen until we successfully drained Container Instance (worst case is around 10 hours).
Step Scaling policies does not have this problem. Scaling Out action can happen while Scaling In action is not completed yet. However, Scaling In action would not happen, if another Scaling In action is being executed.
We decided that Step Scaling fits our needs.
ECS Task Role
Every container just like every EC2 instance might need some way to call AWS APIs (like access to S3 objects). For EC2 instances you can use Instance Profiles. Similar approach exists for ECS containers called Task Roles. See documentation on Task roles
In general it works in a similar way:
AWS_CONTAINER_CREDENTIALS_RELATIVE_URIis generated (contains path) and it is passed as environment variable to container- AWS SDK in container queries special IP + URI for credentials and uses those credentials for making requests to AWS APIs
Please note that you may need to upgrade SDK to use this feature.
Not so obvious thing from documentation is proper sts:AssumeRole permission for policies. Very useful thing to know if you’re putting policies in CloudFormation templates.
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Statement:
- Effect: Allow
Principal:
Service: [ecs-tasks.amazonaws.com]
Action: ['sts:AssumeRole']
Policies:
...
Logging
Jobs generate lots of logs, which are useful for finding and tracking issues. We don’t want each job to have separate logging infrastructure. For logging we had good experience with ElasticSearch + Kibana setup running where we search / view log messages. So we wanted to keep same logging infrastructure, but adapt it for ECS.
ElasticSearch stack
AWS offers managed ElasticSearch service that comes together with Kibana. Since it’s managed service (we don’t need to maintain EC2 machines for it, etc) it makes a lot of sense to use it:
Currently it is possible to launch AWS ES service using CloudFormation template. That was not possible when AWS ES service launched. There are quite a few caveats associated with launching AWS ES:
- You need to choose appropriate instance type if you consume a lot of logs / search lots lots of logs
- Old indexes are not deleted automatically (possible to get into out of space situation). But there are Lambda solutions in the wild which automates that.
- You have to be careful when specifying options in CloudFormation for AWS ES. We ran into a case that if you miss
rest.action.multi.allow_explicit_index: truein CloudFormation template – ES cluster fails to stabilize and you don’t get clear error message about it - Permission model is quite hard to get right. There are basically two options for accessing ES
- IP Whitelist based access – convenient for allowing specific IPs to access Kibana interface. IPs of agents pushing logs to ES. IPs whitelist does not work if instances have Public IP which is changing unless you allow access from “World” but that’s bad idea even for testing
- Requests signed by AWS v4 signing algorithm. Signing algorithm makes it kinda hard to use, because client needs to implement signing algorithm and very few clients has that implementation out of the box. One example how it could be used to create a proxy using AWS v4 signing.
- ElasticSearch service currently does not support
ShieldorMarvelplugins for access control
Pushing logs to ElasticSearch
We’re using fluentd to process logs, because we need to do some processing on log messages before sending those to ElasticSearch.
There is fluent-plugin-elasticsearch that allows us to forward logs to ElasticSearch. This works out of the box. Only drawback is: fluent uses plain HTTP requests to send logs. This means we have to explicitly allow our machines that send logs to access ElasticSearch without authentication by whitelisting IPs of machines that send logs
Ideally we’d like to use AWS v4 signing for requests so that we would not need to care about IPs of machines. There is fluent-plugin-aws-elasticsearch-service that extends fluent-plugin-elasticsearch by adding AWS v4 signing to requests. It works, but there are couple of issues related to this plugin:
- Throws some deprecation warnings (PR available)
- Lacks support for ECS Task Role (but has EC2 instance profile support) (PR available)
- Plugin does not seem to have an active maintainer (at the time of writing last release was almost a year ago)
Adapting jobs
- Writing logs to files in a container is bad idea because of persistance and ease of access
- If logs are written to files each container would need to run some agent to push logs or share log files through volume mounts in some peculiar way.
- It would be far more convenient if each container would output logs to stdout and some other application on top would have a responsibility to push logs to ElasticSearch
- Very convenient for development, since you don’t need to know where application stores logs,
docker logswould be sufficient
In general we want jobs containers to follow The Twelve-Factor App principles which play nice with cloud and Docker. Main points to be taken from Twelve-Factor App:
- Logs are written to stdout
- Configuration is passed through environment variables
Docker logging facilities
As mentioned above we would like logs to be written to stdout of containers and Cluster itself would be responsible for forwarding logs to ElasticSearch. This can be achieved with logging facilities of Docker itself.
Similar blog post on connecting ECS + fluentd logging
- Configure Constainer Instances to use fluentd driver. Note that fluentd driver is not available in old versions Docker
echo ECS_AVAILABLE_LOGGING_DRIVERS=[\"json-file\",\"syslog\",\"fluentd\"] >> /etc/ecs/ecs.config
- Launch fluentd container in each ECS Container Instance (assuming TaskDefininion is available). See AWS blog post on Running an Amazon ECS Task on Every Instance. Note: This should also be added to any init script (such as upstart or systemd) so that the rebooted instance starts the task.
instanceArn=$(curl -s http://localhost:51678/v1/metadata | jq -r '. | .ContainerInstanceArn' | awk -F/ '{print $NF}' ) region="eu-west-1" aws ecs start-task --cluster ${ECSCluster} --task-definition "FluentD" --container-instances $instanceArn --region $region
- Each TaskDefinition that runs on Cluster should have logging driver set to fluentd and NetworkMode to
host(reasoning in next section).Properties: ... NetworkMode: host LogConfiguration: LogDriver: fluentd Options: fluentd-address: localhost tag: application.name
Why do we have one container with fluentd per host instance and not just 1 fluentd service in cluster?
There are several reasons behind that decision:
- Service discovery. We don’t have it in our cluster and basically we don’t need it for normal functionality. If we would have
FluentDas service in ECS, then we would need to know IP of the host machine, where fluentd task is actually running. And this IP can change, if service/task will be restarted for one reason or another. - Network roundtrips. In case we will have container with fluentd on another host machine we would need to send our logs over the network. Which is expensive (given the fact that we really generate a lot of logs) and not really secure.
This solution forces us to use “host” networking mode to be able to set fluentd-address: localhost. There is no normal documented way to obtain host machine IP from the container itself (while default IP is known, but it already changed with one minor docker version, so it is not reliable).
Summary
We’ve found a solution on how to run backround processing jobs on ECS cluster in AWS. Using solutions described we were able to set up proper logging and scaling for the cluster. It was interesting dive into ECS and AWS in general.
We ended up creating ECS Cluster for background job processing that scales, collects logs. With some fine-tuning it could be adapted for web applications (by adding ELB / ALB, Service Auto Scaling). We hope that you will find this useful for your projects and you will end up saving time.

One thought on “Running batch jobs in Docker containers on AWS ECS that scales”